
Bisher hatten wir uns im Rahmen der Phonetik mit der materiellen Seite der Laute (also deren Produktion, Verbreitung im Raum und Perzeption) befasst. Schon bei dem Exkurs über den Lautspracherwerb nach Jakobson wird jedoch klar, dass diese Laute auch aus einer funktionalen Perspektive betrachtet werden können und müssen: Laute werden produziert, um Informationen zu vermitteln Mit der Frage, was Laute zur Informationsvermittlung beitragen, befasst sich die Phonologie.
Erinnern wir uns: Auch wenn ein Kind in der Lallphase spontan eine Vielzahl von Lauten produziert, so wird mit Hilfe dieser Laute noch keine Information bzw. Bedeutung vermittelt. Laute und Lautketten gewinnen aber erst Zeichencharakter, wenn ein Sprecher mit ihrer Hilfe einem Hörer Informationen übermittelt.
Welche spezielle Leistung erbringen die einzelnen Laute der Lautfolge einer Wortform wie "(das schmeckt) fein" = [ f ai n ] bei der Übermittlung der betreffenden 'Botschaft'? Eine klassisch strukturalistische Antwort hat der Linguist Trubetzkoy gegeben. Gemäß den Vorstellungen des Strukturalismus müssen wir einzelne Laute als Teil eines Systems (hier des Lautsystems des Standarddeutschen) begreifen. Und in einem System ergibt sich die spezielle Leistung eines einzelnen Elements aus dessen OPPOSITIONen zu den anderen Elementen dieses Systems:
Wie die Schaubilder oben zeigen, genügt es, in einer Lautfolge wie [ f ai n ] einen einzigen Laut gegen einen anderen auszutauschen, und schon haben wir ein anderes Wort vor uns. Wir sagen deshalb, daß die generelle Leistung und Funktion von Lauten im Rahmen von Wortformen darin besteht, die betreffenden Wörter von anderen Worten zu unterscheiden. Laute, die das leisten (oben haben wir das u.a. für [ f ] und [ m ] und [ i: ] gezeigt), nennen wir PHONEME (ein Phonem, zwei und mehr Phoneme). Ein Phonem - ein Laut, der 'Phonem-Status' hat - ist die kleinste bedeutungsunterscheidende Einheit einer Sprache.
Hier einige weitere zentrale Begriffe des Strukturalismus:
Nun können aber zwei und mehr Laute im Rahmen von Minimalpaaren die gleiche bedeutungsunterscheidende Funktion haben. Beispielsweise stellt das gesprochen-sprachliche Paar von Ausdrücken

ein Minimalpaar dar, das für die deutschen Laute [ d ] und [ th ] belegt, daß es Phoneme sind (wechsel ich sie gegeneinander aus, so entsteht ein neues Wort, ein Wort mit einer anderen Bedeutung). Ob ich nun aber bei "Dorf" das anlautende [ d ] stimmhaft oder stimmlos spreche (im Standarddeutschen wird es anlautend an sich stimmlos gesprochen), so ändert das nicht die Bedeutung. Und auch wenn ich - etwa als Franzose oder Französin, der/die mit den aspirierten Formen der Explosivlaute gewisse Schwierigkeiten hat - das anlautende [ th ] nicht-aspiriert spreche (also als [ t ] ), ändert das nichts an der Bedeutung des entsprechenden Wortes "Torf".
In der strukturalistischen Linguistik sprechen wir bei funktionsgleichen Lauten wie [ t ] und [ th ] von Varianten oder Allophonen eines (ein und desselben) Phonems. Um das auch in der schriftlichen Wiedergabe deutlich zu machen, notieren wir das Phonem (wie oben schon angesprochen) in Schrägstrichen, also
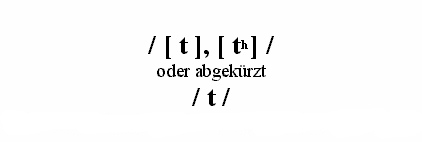
wobei wir in der Regel bei der abgekürzten 'Phonem-Schreibung' die einfachere Allophon-Notation verwenden.
5.1.2. Kombinatorische und frei wählbare Allophone
Wie das o. g. Beispiel zeigt, gibt es offenbar für (manche) Allophone – wie z. B. aspirieretes vs. nicht aspiriertes / t / - feststehende Regeln, wann sie verwendet werden. So wird die aspirierte Variante vor Vokalen und im Silben- und Wortauslaut gewählt (wobei der Grad an Aspiration in betonten Silben deutlich höher ist als in unbetonten Silben; nicht-aspiriertes / t / wird vor folgendem Konsonant gewählt. Allophone dieser Art nennt man kombinatorische Allophone, weil sie eben jeweils in Abhängigkeit von der lautlichen Umbebung. Anders dargestellt darf die eine Variante in solchen Kontexten nicht auftreten, wo die andere auftritt; beide Kontextmengen zusammen machen dann wieder das Ganze der Verwendung eines solchen Phonems aus, - wir sprechen deshalb auch von der komplementären Distribution oder Verteilung mehrerer Allophone ein- und desselben Phonems.
Es gibt aber auch Allophone, für die es keine Regeln gibt, wann welche Variante aufzutreten hat. Ein Beispiel hierfür wären die Allophone des / r / - Phonems: Ob ich "Recht", "Rübe" etc. mit frikativem Rachen-R oder als Vibrant spreche ist völlig egal und folgt auch keiner Ausspracheregel (es verrät allenfalls etwas über die Herkunft oder den Beruf des Sprechers – das Vibranten- / r / wird auch als Bühnen - / r / bezeichnet, weil es auch über größere Distanzen gut hörbar ist. Solche Allophone nennt man frei wählbare Allophone.
5.1.3. de Saussure und die Phonetik / Phonologie
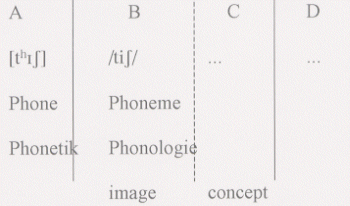
Erst die Phonologie gehört (in Anlehnung an die Vorstellungen von de Saussure vom sprachlichen Zeichen) zur Sprachwissenschaft; die Phonetik ist eigentlich noch ein Teil der Biologie (artikulatorische und auditive Phonetik) oder der Physi (akustische Phonetik); erst wenn man sich mit Phonemen beschäftigt, befindet man sich auch 'innerhalb des de Saussurschen Zeichens', nämlich im Bereich der 'images' (nur die Abschnitte B und C der folgenden Graphik stellen das Zeichen dar!).
Wir erinnern uns an Saussures zweiseitiges Zeichenmodell. Phonetik und Phonologie werden den Bereichen A und B wie folgt zugeordnet:
5.2.1. Funktionale Betrachtungsweise
Die Begriffe 'Phon' und 'Phonem' verraten ein je spezifische Sicht: Von Phonen haben wir gesprochen, wenn es (am Beispiel der artikulatorischen Phonetik) um spezifische artikulatorische Bewegungsfolgen ging. Der Begriff 'Phon' ist auf eine materielle Beschreibung von Lauten festgelegt. Ganz anders der Begriff 'Phonem', der die funktionalen Aspekte einer Lautbildung aufgreift: Phoneme sind (wie gesagt funktional orientiert) die kleinsten bedeutungsunterscheidenden Segmente einer (Laut- bzw. gesprochenen) Sprache.
Nun kennen wir nicht nur die Funktion, die Bedeutung von Ausdrücken lautlich voneinander zu unterscheiden. Sondern wir sprechen auch davon, dass eine Kette von Phonemen (selten auch ein einzelnes Phonem) eine Bedeutung TRÄGT. Beispielsweise trägt die Phonemfolge (hier in der alltäglichen Verschriftung wiedergegeben) "Auto" eine spezifische lexikalische Bedeutung, wie sie etwa in den gängigen Wörterbüchern in Form von Paraphrasen ('das Gleiche mit anderen Worten') wiedergegeben wird. Hinzu kommt bei "Auto-s" ein zweites Segment (diesmal aus nur einem Phonem bestehend), das als Bedeutung festhält, dass es sich um mehrere Autos handelt (wir sprechen hier von Plural; aber Achtung: der Plural drückt nicht immer und nicht notwendigerweise 'Mehrzahl' aus).
In den folgenden Ausführungen geht es erneut um eine funktionale Betrachtung, dabei aber um die Frage, welche bedeutungsTRAGENDE Funktionen ein Phonem oder eine Phonemfolge hat.
Auto-s" besteht aus Segmenten, die jeweils eine klar erkennbare Bedeutung TRAGEN. Dabei sprechen wir bei "Auto" von lexikalischer Bedeutung, wie sie in Lexika durch Paraphrase ('das Gleiche mit anderen Worten') wiedergegeben wird. Bei "-s" handelt es sich um eine grammatische Bedeutung, den Plural, der - nicht immer, aber hier - 'bedeutet'. Vergleichbar besteht "lach-t-e" oder "mach-t-e", aber auch eben "Lach-/-e" (= "lache") oder "wein-/-e" (= "weine" aus drei Segmenten, die ebenfalls jeweils eine klar erkennbare Bedeutung tragen und als Segmente (mit der gleichen Bedeutung) auch in anderen Zusammenhängen auftreten:

Hier erneut einige zentrale Begriffe:
 Es
geht hier jetzt um kleinste bedeutungsTRAGENDE Segmente, also um Zeichen
im Sinne de Saussures, die über ihre Ausdrucksseite hinaus (= image) eine Bedeutung
tragen (= concept). Und wenn die obige Segmentation korrekt wäre, dann müsste sie auch
für die Inhaltsseite zutreffen; dann müsste sich die Bedeutung von "(ich)
l-ach-(e)" oder "(ich) m-ach-(e)" aus der Bedeutung von "m-" bzw.
"l-" und dann der Bedeutung von "-ach-" zusammensetzen (etwa so, wie
sich die Bedeutung von "Schaltzentrale" aus der Bedeutung von
"Schalt-" (vgl. das Verb "schalten") und "-zentrale"
zusammensetzt. Was aber hat "m-" für eine Bedeutung, was für eine Bedeutung
drückt "-ach-" aus? Keine !!! Das Ganze ist schlicht Blödsinn. Ein Verbstamm
wie "mach-" oder "lach-" läßt sich eben nicht weiter in kleinere,
noch eine eigenständige Bedeutung tragende Subsegmente zerlegen !!!
Es
geht hier jetzt um kleinste bedeutungsTRAGENDE Segmente, also um Zeichen
im Sinne de Saussures, die über ihre Ausdrucksseite hinaus (= image) eine Bedeutung
tragen (= concept). Und wenn die obige Segmentation korrekt wäre, dann müsste sie auch
für die Inhaltsseite zutreffen; dann müsste sich die Bedeutung von "(ich)
l-ach-(e)" oder "(ich) m-ach-(e)" aus der Bedeutung von "m-" bzw.
"l-" und dann der Bedeutung von "-ach-" zusammensetzen (etwa so, wie
sich die Bedeutung von "Schaltzentrale" aus der Bedeutung von
"Schalt-" (vgl. das Verb "schalten") und "-zentrale"
zusammensetzt. Was aber hat "m-" für eine Bedeutung, was für eine Bedeutung
drückt "-ach-" aus? Keine !!! Das Ganze ist schlicht Blödsinn. Ein Verbstamm
wie "mach-" oder "lach-" läßt sich eben nicht weiter in kleinere,
noch eine eigenständige Bedeutung tragende Subsegmente zerlegen !!!
Gegenstand ist eine
funktionale Beschreibung der Segmente menschlicher Rede. Neben der Funktion (der Phoneme),
bedeutungsunterscheidend zu wirken, haben wir oben die Funktion oder Leistung von
Segmenten kennengelernt, eine Bedeutung zu tragen bzw. auszudrücken. Tragen zwei Segmente
die gleiche Bedeutung, so sind sie funktionsgleich. - Was bedeutet
"-st" (z.B. in "du lach-/-st")? Es drückt die 2te
Pers.Sg. aus.
"-est" (z.B. in "du lach-t-est")? Es drückt die 2te
Pers.Sg. aus.
Folglich sind die (kleinsten bedeutungstragenden) Segmente "-st" und
"-est" funktionsgleich. Funktionsgleiche Segmente, die physikalisch-materiell
verschieden sind, nennen wir Varianten (vgl. die entsprechende Definition der Varianten
eines Phonems, also der Allophone); genauer sprechen wir von den Varianten eines Morphems
oder von Allomorphen. Auch die Segmente "-st" und
"-est" angewendet handelt es sich hier um zwei Allomorphe des 2te
Pers.Sg.-Morphems.
Was bedeutet in "Auto-s" das "-s", in "Boot-e" das "-e" (Achtung: das ist ein anderes "-e" als in "(ich lach-/-)-e"), in "Frau-en" das "-en" usw.? Nun stets das Gleiche, - alle diese Schlußsegmente sind funktionsgleich und drücken den Plural aus, - es handelt sich um Allomorphe des standarddeutschen Plural-Morphems.
5.2.3. Kombinatorische und frei wählbare Allomorphe
Schon bei den Varianten oder Allophonen eines Phonems war die Frage gewesen, ob sie frei wählbar sind oder nicht. Gleichartig fragen wir auch hier, ob die Varianten oder Allomorphe eines Morphems frei wählbar sind oder nicht. - Es gibt im Rahmen der Morphologie nur wenige frei wählbare Allomorphe; beispielsweise können wir in jedem Kontext "Tür" gegen "Türe" austauschen. Meistens jedoch handelt es sich um kombinatorische bzw. komplementär verteilte Varianten bzw. Allomorphe eines Morphems.
Entsprechend analysiert die strukturelle deskriptive Sprachwissenschaft wie folgt:
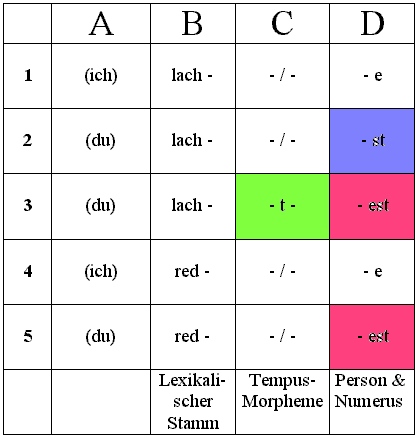
Hier haben wir es im Paradigma der Person- & Numersusendungen (= Spalte D) neben dem Allomorph "-st" (Zeile 2) mit dem Allomorph "-est" (Zeile 3 und Zeile 4) zu tun. Beide bedeuten das Gleiche, beide sind also funktionsgleich, aber der materiellen Substanz nach unterschiedlich; mithin handelt es sich um (die) zwei Allomorphe des "2.te Pers. St. Morphems". Eben diese Morpheme sind ersichtlich nicht frei wählbar, also komplementär verteilt.
Die Zeilen 2 und 3 könnten nahelegen, dass die Verteilung dem grammatischen Kontext folgt (einmal Präsens, zum anderen Präteritum - vgl. Spalte C ). Doch gibt es auch Kontexte wie die Zeile 5, die im Vergleich mit der Zeile 2 gleichermaßen Präsens ausdrückt. Offensichtlich ist es also nicht der grammatische Kontext, der die Verteilung regelt, sondern der lautliche Kontext: Stoßen an einer Morphem-Segmentgrenze zwei ortsgleiche Konsonanten aufeinander und drohen auf diese Weise, ineinander verschliffen zu werden (so dass die Morphem-Segmentgrenze als solche nicht mehr erkennbar ist), dann obsiegt gewissermaßen der Hörer, der verstehen will, über den Sprecher, der mit möglichst wenig Aufwand artikulieren will (und also verschleift); dann schieben die Sprecher einen 'Restvokal' ein (und aus "-st" wird "-est"), um die Verschleifung letztlich der Morphem-Segmentgrenze zu verhindern.
In Zeile 3, Spalte C (das grüne Feld), tritt ein Mittelsegment "-t-" auf, das Präteritum ausdrückt. Bilden wir das Präteritum von "reden", dann ergibt sich - dabei sowohl für "lachen" wie für "reden (vgl. in der folgenden Darstellung die Opposition von grünem und gelbem Feld, C-3 vs. C-4):
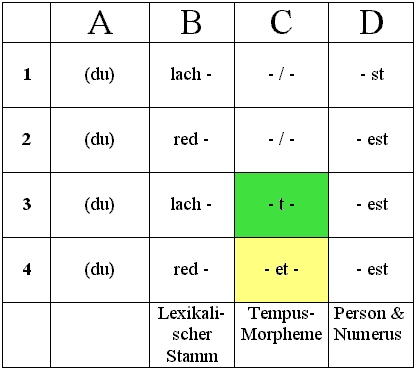
Ersichtlich handelt es sich hier um (die) zwei Allomorphe des Präteritum-Morphems, die erneut komplementär verteilt sind. Und: Ersichtlich folgt die Verteilung der zwei Allomorphe erneut dem lautlichen Kontext. Und schließlich: Auch hier dürfte gewissermaßen die Grundform "-t-" sein, dem dann ein Restvokal vorangestellt wird (= "-et-"), wenn an der betreffenden Morphem-Grenze zwischen dem Stamm und dem Präteritum-Morphem 'zwei ortsgleiche Konsonanten aufeinander treffen und so die Morphemgrenze zu verschwinden droht'.
Nun gibt es nicht nur komplementär verteilte Allomorphe, die abhängig vom lautlichen Kontext verteilt sind, sondern es gibt zwei Typen der Verteilung von Varianten (darin also unterscheidet sich die Morphem-Ebene von der Phonem-Ebene, die nur einen Typus der Verteilung von Varianten kennt); neben eine Verteilung gemäß lautlichen Kontext tritt (in der Tat - siehe dazu schon oben) eine Verteilung gemäß grammatischem Kontext. Ein schönes Beispiel hierfür sind Phänomene im Rahmen der Steigerung, auf die wir allerdings erst im Rahmen einer Unterscheidung von sog. lexikalischen vs. grammatischen Morphemen zu sprechen kommen wollen.
5.2.4. Lexikalische und grammatische Morpheme
Innerhalb der obigen Segmentierungen lassen sich zwei Typen an Morphemen unterscheiden, einmal die Verbstämme "lach-", "red-" oder "mach-" usw., zum anderen die Präteritum-Morpheme, die Person-Numerus-Morpheme, aber auch etwa das Plural-Morphem usw.. Eine erste Erläuterung könnte sein, dass wir z.B. Verbstämme im Lexikon finden, - wir sprechen auch von lexikalischen Morphemen; hingegen finden wir etwa Tempus-Morpheme oder das Plural-Morphem in der Grammatik erklärt und sprechen deshalb auch von grammatischen Morphemen.
Es gibt in der strukturell-beschreibenden Linguistik eine Vielzahl von Versuchen, den Unterschied von lexikalischen und grammatischen Morphemen (und damit den Unterschied von Grammatik und Lexikon) genauer zu bestimmen. Einigermaßen Konsens haben Beschreibungen der folgenden Art gefunden:

Zu den grammatischen Morphemen gehören auch die Artikel oder Präpositionen; diskutiert wird sogar, ob nicht auch Pronomina wie "er" oder "du" dazugehören. Doch inwiefern 'variieren sie die Bedeutung lexikalischer Morpheme oder drücken deren Zusammenhang innerhalb einer Äußerung aus'? Allerdings lassen sich vergleichbare kritische Nachfragen auch etwa zum Plural oder zum Präteritum formulieren; doch drückt eben der Plural nicht immer 'Mehrzahl' und ein Präteritum-Morphem nicht immer 'Vergangenheit' aus. - Wir können die Debatte hier nicht weiter verfolgen.
Ein formales Kriterium wäre es, zu sagen, grammatische Morpheme würde geschlossene Systeme bilden, die man nicht einfach erweitern könne, so das Tempus-System oder das Person-Numerus-System. Und die lexikalischen Morpheme würden dagegen offene Systeme bilden, die man ohne weiteres erweitern könne; wie steht es dann aber mit dem lexikalischen System der Monatsnamen oder der Tagesnamen, die man ja auch nicht ohne weiteres erweitern kann? - Auch hier können wir die Debatte nicht weiter verfolgen.
Wir können an dieser Stelle zum Abschluß noch einmal die Verteilung komplementär verteilter Allomorphe eines Morphems aufgreifen. Es gibt nicht nur die Verteilung gemäß lautlichem Kontext, sondern auch gemäß grammatischem Kontext, wie das folgende Beispiel aus dem Bereich der Steigerung von Adjektiven belegt:
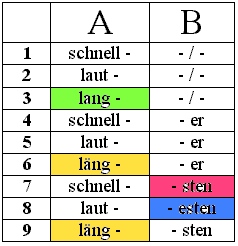
Wir haben es hier bei B-7 vs. B-8 wieder mit zwei komplementär verteilten Allomorphen (des Superlativ-Morphems) zu tun, die gemäß lautlichem Kontext verteilt sind (siehe dazu schon ausführlich weiter oben). Bei A-3 vs. A-6 oder A-9 jedoch liegen zwei Allomorphe ein- und desselben lexikalischen Morphems vor, die gemäß grammatischem Kontext verteilt sind: Im Komperativ und Superlativ und z.B. auch bei der Substantivierung wird "läng-" verwendet.
Historisch lassen sich allerdings auch Variationen wie "lang-" vs. "läng-" oder "Hut-" vs. "Hüt-" (z.B. in "Hüte") oder "Dorf-" vs. "Dörf-" (z.B. in "Dörfer") als komplementäre Verteilungen gemäß lautlichem Kontext rekonstruieren; doch haben sich die Ursprungsverhältnisse inzwischen so sehr weiterentwickelt, dass daraus eine Verteilung nach grammatischem Kontext geworden ist. - Im einzelnen müssen früher Endungen wie "-er" oder auch "-e" (z.B. in "Hüt-e") ein "i" enthalten haben, das auf den Stammvokal zurückgewirkt hat (regressive Assimilation, die zur Entstehung sog. Umlaute geführt hat). Man kann sich gut vorstellen, dass hier - Sprecher orientiert - zunehmend ökonomisch artikuliert wurde und unser der 'i-haltigen' Endung vorangehender Stammvokal (z.B. das "a" in "lang-") gewissermaßen artikulatorisch auf das folgende "i" zu bewegt wurde:
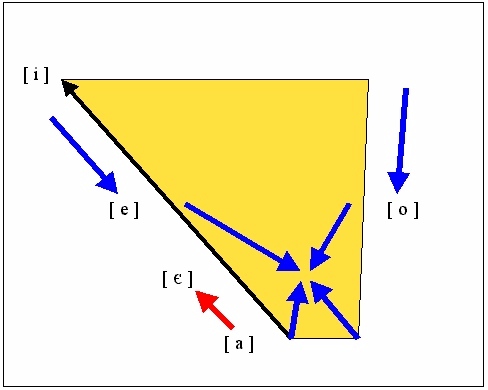
Die oben mit einem roten Pfeil markierte regressive Assimilation (artikulatorische Annäherung des "a" (= [ a ] ) an das folgende "-ir" oder "-i" usw. wäre wahrscheinlich so weit vorangeschritten, dass daraus schließlich ein "i" geworden wäre (also etwa *"ling-ir" statt - heute - "läng-er"), wenn nicht zu einem bestimmten Zeitpunkt das folgende "i" (also das "i" in der Endungssilbe) verfallen und abgebaut worden wäre (vgl. die blauen Pfeile). - Zu Details vergleiche die Darstellung der 'Restvokale der unbetonten Silben' im Rahmen des Phonetik-Kapitels).
Häufig irritiert gerade bei den grammatischen Morphemen, dass sie hochgradig mehrdeutig sind. Doch ist das ein Phänomen, das sich auch für lexikalische Morpheme belegen läßt; wir machen uns - glaube ich - nicht klar, in welchem Ausmaß auch lexikalische Morpheme mehrdeutig sind. Vgl. zu solchen Mehrdeutigkeiten lexikalischer wie grammatischer Morpheme:

Die Mehrdeutigkeit lexikalischer Morpheme wird auch in neurolinguistischen Testmaterialien genutzt, so in Tests zur Kontextverarbeitung bei einer dementiellen Erkrankung wie der Alzheimer-Krankheit. Die folgende Abbildung zeigt eine Mehrdeutigkeit, aber dargeboten in einem eindeutigen Kontext, was zur 'Vereindeutigung' ('Monosemierung') des mehrdeutigen Ausdrucks führt. Ebenfalls angeboten werden zwei Bilder, die sich auf die beiden Bedeutungsmöglichkeiten des mehrdeutigen lexikalischen Morphems beziehen. Aufgabe der Testperson ist es nun, den dargebotenen Satz mit dem mehrdeutigen Ausdruck (der im Satzzusamenhang aber - wie ausgeführt - eindeutig ist) auf das passende Bild zu beziehen:
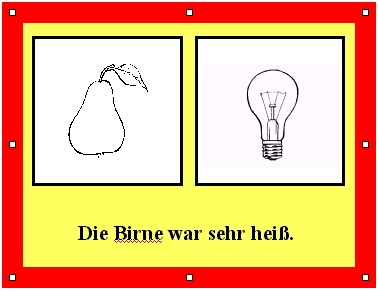
Gesunde Probanden ordnen den Satz spontan dem rechten Bild zu (obwohl es ja auch heiße Birnen in Rotwein als Leckerei git). - Patienten mit einer Alzheimer-Krankheit können die hier notwendige Vereindeutigung auf 'Glühbirne' (üblicherweise kann nur diese heiß werden) nicht mehr spontan durchführen und haben deshalb Schwierigkeiten, den Satz einem der beiden Bilder zuzuordnen.
Bei Mehrdeutigkeit sprechen wir auch von Homonymie. Wenn zwei Ausdrücke (mit unterschiedlicher Bedeutung) nur gleichlautend sind, aber unterschiedlich geschrieben werden (z.B. das Indefinit-Pronomen "man" und das Substantiv "Mann" oder "mehr" vs. "Meer"), dann sprechen wir genauer von Homophonie. Wenn zwei Ausdrücke nur gleich geschrieben werden (aber unterschiedlich ausgesprochen werden), dann sprechen wir von Homographie. Man vergleiche das Verb "modern" im Unterschied zum Adjektiv "modern". Oder man vergleiche "Druckerzeugnis" = (a) Resultat eines Druck-Vorgans, (b) Zeugnis für einen Drucker, die jeweils auch anders gesprochen (aber eben identisch geschrieben) werden.
Neben mehrdeutigen Ausdrücken (eine Ausdrucksseite bzw. ein image ist mehreren Inhalten bzw. 'Konzepten' zugeordnet) kennen wir auch den Fall, dass ein- und derselbe Inhalt (concept) mithilfe mehrerer Ausdrücke (bzw. Ausdrucksseiten, - 'image' im Sinne de Saussures) ausgedrückt werden kann. Wir sprechen in diesem Fall von 'Synonymie'. Echte Synonymie (d.h. zwei und mehr Ausdrücke geben vollständig den gleichen Inhalt wieder) ist höchst selten.
5.3.2. Grammatische Morpheme als Teil des Lexikons ?
In neueren Überlegungen der Linguistik werden die grammatischen Morpheme nicht mehr als Teil der Grammatik, sondern als Teil des Lexikons aufgefaßt. Das macht u.a. im Rahmen der Wortbildung Sinn, die ebenfalls heute als Teil des Lexikons gerechnet wir; entsprechend werden Prozesse, die ein Adjektiv wie "krank" mithilfe eines sogenannten Ableitungsmorphems (ein grammatisches Morphem) zu einem Substantiv oder Nomen machen ("krank" > "Krank-heit", "glaubwürdig" > "Glaubwürdig-keit"), als lexikalische Prozesse aufgefaßt. Das gilt gleichartig z.B. für Ableitungen, die aus einem Substantiv oder Nomen ein Adjektiv machen, - vgl. "Sand" > "sand-ig", "Gewalt" > "gewalt-ig" oder "Gift" > "gift-ig".
Ich möchte vorgreifend schon hier festhalten, dass neueste neurolinguistische Studien ein gänzlich anderes Bild malen. Danach sieht es eher so aus, als ob alles, was regelhaft ableitbar ist (also auch z.B. regelhafte Fälle von Wortbildung), Teil des sog. prozeduralen Gedächtnisses ist und auf Seiten der linken (dominanten) Hemisphäre frontal 'gemacht' wird ('sprachliche Prozeduren' als Gegenstand der Grammatik?). Umgekehrt gehören irreguläre Formen der Wortbildung, der Pluralbildung, der Bildung eines Partizips (traditionellerweise also auch eine Reihe grammatische Phänomene) ins deklarative Gedächtnis (Gedächtnis für Faktenwissen), das (ebenfalls links-hemisphärisch) temporal-parietal 'gemacht' wird ('singuläre sprachliche Speicherungen' als Gegenstand des Lexikons?).
Wir können diese Neuentwicklungen - so spannend sie sind - hier leider nicht weiter verfolgen.
Überlegenswert sind ebenfalls Überlegungen, wie sie die sog. Valenzgrammatik (dazu weiter unten mehr) und neuerdings auch Autoren wie Levelt anstellen. Danach ist im klassischen Lexikon nicht nur die Bedeutung (concept) oder der Inhalt oder die Funktion eines Ausdrucks gespeichert, sondern auch eine Reihe syntaktischer Aspekte (auch dazu weiter unten mehr), die ich bei Abwahl eines entsprechenden lexikalischen Morphems aus dem Lexikon mit abwähle.
Wenn ich beispielsweise ein Verb wie "wohn-" (Infinitiv "wohnen") aus dem Lexikon abwähle, dann wähle ich auch eine Reihe von syntaktischen Festlegungen mit ab; beispielsweise darf ich nach "Ich wohne ..." nicht fortfahren z.B. mit einem Akkusativ-Objekt: Äußerungen wie die folgende sind syntaktische falsch:
*Er wohnt die Stadt Freiburg.
Ein Stern vor einem Ausdruck bedeutet, dass es den Ausdruck nicht gibt bzw. dass der Ausdruck fehlerhaft ist. - Richtig wären hingegen Äußerungen wie
Er wohnt in der Stadt Freiburg.
In der Schulgrammatik hat man mit Blick auf Verben auch von der Rektion eines Verbs gesprochen. Im Rahmen der Valenzgrammatik spricht man auch von der Valenz eines Verbs, die mich natürlich nicht nur syntaktisch, sondern auch semantisch oder bedeutungsmäßig festlegt (ich kann beispielsweise "sehr schön wohnen", kann aber nicht "sehr gelb wohnen").
Oben wurde bereits erörtert, dass wir zwischen lexikalischen und grammtischen Morphemen unterscheiden. Im folgenden noch einige weitere Unterscheidungen und Grundbegriffe:
Die Unterscheidung ist umstritten, da sie sich nur auf die Schriftsprache mit den hier konventionell festgelegten Wortgrenzen beziehen läßt. Im Gesprochenen hingegen verbinden wir - abhängig vom Sprechtempo - auch im Deutschen gegebenenfalls mehrere durch Zwischenraum getrennte schriftsprachliche Segmente zu einer einzigen artikulatorischen Ganzheit.
5.4.1. Zur Parallelisierung von Phonologie und Morphologie
Wenn wir uns noch einmal rückblickend vergewissern, dann erkennen wir, daß die Phonologie und die Morphologie völlig parallel aufgebaut sind, auch wenn es sich einmal um kleinste bedeutungsunterscheidende Einheiten, zum anderen um kleinest bedeutungstragende Einheiten handelt:

Zur Erinnerung: Der einzige Unterschied ist, dass es im Rahmen der komplementären Verteilungen bei den Allomorphen zwei Typen gibt, einmal gemäß lautlichem Kontext, zum andere gemäß grammatischem Kontext.
5.4.2. Doppelte Gliederung - Warum 'doppelt gegliedert'? Das Ökonomie-Prinzip
André Martinet - ein Strukturalist der sog. Pariser Schule - spricht in unserem Zusammenhang von der "double articulation" natürlicher Sprachen, von der doppelten Gliederung, die - so führt er aus - sehr ökonomisch sei. Wir seien in der Lage, mithilfe von nur 25 bis 35 Phonemen die ungeheuer vielen Morpheme einer natürlichen Sprache bzw. deren Ausdrucksseiten (image) zu bilden (wir können gerade mit Blick auf das Lexikon davon ausgehen, dass ein 'native and educated speaker' zumindest passiv über mehr als 10.000 bis 15.000 Lexikoneinträge verfügt, die allerdings teilweise aus mehr als nur einem einzigen lexikalischen Morphem bestehen).
Künstliche Sprachen (wie die Prädikaten- oder Aussagenlogik oder mathematische Sprachen) verfügen in der Regel nicht über die doppelte Gliederung. Hier haben die Grundelemente in der Regel bereits die Größenordnung eines kleinsten bedeutungstragenden Segmentes, eines Morphems.
Die doppelte Gliederung natürlicher Sprachen betrifft zunächst nur deren gesprochene Variante. Und wie steht es um die Schriftsprache? - Wir müssen verschiedene Schriftsysteme (Systeme von Schriftzeichen) unterscheiden. In einer Schriftsprache wie dem geschriebenen Deutsch benutzt man Buchstaben bzw. (als Gesamtheit der Buchstaben) ein Alphabet, - das schriftliche Deutsch arbeitet mit einer Alphabetschrift. Hier liegen vergleichbare Verhältnisse wie bei der gesprochenen Sprache vor: Auch das geschriebene Deutsch ist 'doppelt gegliedert'.
Es gibt verschiedenste Alphabetschriften. So unterscheidet sich die koreanische Alphabetschrift drastisch von unserer Alphabetschrift, die ursprünglich auf die Phönizier zurück; die Römer übernahmen deren Schriftsystem und änderten es bis (annähernd) zur heutigen Form ab.
Wir haben eingangs - im Zusammenhang ikonischer Zeichen - auch bereits andere Schriftsysteme kennengelernt; ein extremes Gegenstück zu Alphabetschriften sind Bildschriften, deren Grundelemente - wie bei künstlichen Sprachen - bereits kleinsten bedeutungstragenden Segmenten entsprechen. Ich erinnere an die chinesische Schrift, deren frühe Vorformen bestens als Abbildungen dessen erkennbar sind, was sie darstellen. Vgl.

Eine Wand in der chinesischen Provinz Szetschuan
(aus: G.A. Miller [1993], Wörter - Streifzüge durch die Psycholinguistik, Heidelberg:
Spektrum, S. 58)
Schriftzeichen einer Bilderschrift haben die Größenordnung kleinster bedeutungstragender Segmente, so hatte ich ausgeführt. Wieviele Alphabetschriftzeichen verwenden wir in den westlichen Sprachen? Zirka 25 bis 30 Zeichen! Und wieviele Schriftzeichen werden im Rahmen von Bilderschriften verwendet? Nun, tendenziell so viele, wie es Morpheme in dieser Sprache gibt, also tausende von Bildschriftzeichen! Wielange braucht ein Kind in Deutschland, um Lesen und Schreiben zu lernen? Nur wenige Jahre! Und wieviele Jahre braucht man, um das Lesen und Schreiben in einer Bilderschrift zu lernen? Tendenziell ein ganzes Leben, - im Chinesischen wird der Schreib- und Lesekundige auch gerne mit dem Weisen gleichgesetzt.
Der Vergleich von Alphabetschriften mit Bilderschriften macht noch einmal auf die enorme Ökonomie 'doppelter Gliederungen' aufmerksam, die dazu führt, dass in Gesellschaften mit einer Bilderschrift zunehmend zusätzlich oder sogar in Ersatz eine Alphabetschrift eingeführt wird.
Bearbeiten Sie die folgenden Aufgaben:
(1a) In welcher Region des Großhirns (= Cortex) sind vermutlich die komplexen artikulatorischen Bewegungsentwürfe gespeichert, denen ich folge, wenn ich z.B. "(Da haben Sie ja nochmal) Glück (gehabt)" ausspreche?
(1b) Was ist im Kontext des Beispiels aus (1a) das Besondere an der Artikulation des anlautenden Verschlusses?
(2a) Beschreiben sie (mit phonetisch-artikulatorischen Begriffen), um was für einen Laut es sich bei [ ç ] in [ I ç ] handelt.
(2b) "(Du) redest (daher, als ob du von nichts wüßtest!)": Analysieren sie morphologisch "redest"!
Zu (1a): Vermutlich sekundär-motorische Regionen (vor den primär-motorischen Regionen gelegen), in der Nähe der Sylvischen Furche (also die Broca-Region), in der dominanten (üblicherweise linken) Hemisphäre.
Zu (1b): Wir ziehen in die Verschlußbildung hinein (a) die Ausbildung eines mit den Lippen gebildeten 'Ansatzrohrs', die an sich erst zur Artikulation von "ü" gehört, und (b) biegen wir (zeitlich leicht nach dem Vorstülpen der Lippen) die Zungenspitze nach oben, wie das eigentlich erst zum artikulatorischen 'Programm' des "l" gehört (wir könnten hier auch von 'Koartikulation' sprechen).
Zu (2a): Es handelt sich um einen Frikativ, fortis - stimmlos, palatal gesprochen, der sog. "ich-Laut"; der "ich-Laut" und sein velares 'Gegenstück', der sog. "ach-Laut", bilden zwei Allophone ein- und desselben Phonems.
Zu (2b): Die Substitutionstests (paradigmatische Ersetzungsversuche) ergeben als Segmentation "red-" + "-/-" + "est". Dabei ist "red-" der Verbstamm (mit entsprechender lexikalischer Bedeutung); das 'Null-Segment' in der Mitte drückt Präsens aus (in Opposition zu einem "-t-", das Präteritum ausdrücken würde); und "-est" ist ein Allophon (zweites Allophon: "-st") des 2.Pers.Sg.-Morphems. - Die Allomorphe "-st" und "-est" sind komplementär verteilt, abhängig vom lautlichen Kontext. Genauer wird durch Einschieben eines Restvokals ("e") verhindert, dass an der Morphemgrenze zwei ortsgleich artikulierte Konsonanten direkt aufeinandertreffen und verschliffen werden.
(1) Nennen und erläutern Sie die drei Testverfahren, die wir in der strukturell-deskriptiven Linguistik kennengelernt und bei der Satzanalyse angewandt haben.
(2) Geben Sie pro Testverfahren ein eigenes Beispiel, an dem Sie erläutern, wie jeweils ein Testverfahren funktioniert.
(3) "Das Gebäude brannte lichterloh". - Geben Sie eine vollständige Valenzbeschreibung des standarddeutschen Verbs "brennen".
Zu (1): Substitutionstest = Versuch, paradigmatisch auszutauschen bzw. zu überprüfen, ob es zu einem hypothetisch angenommenen Segment ein ganzes Paradigma hier ersatzweise einsetzbarer Ausdrücke und Ausdruckskomplexe gibt. Verlangt wird nur, dass dabei wieder ein grammatisch korrekter Satz entsteht.
Permutationstest = syntagmatisch die Segmente umstellen (dabei bleibt die Bedeutung natürlich nicht gleich, - verlangt wird nur, dass wieder ein grammatisch korrekter Satz entsteht). - Der Permutationstest zeigt, welche Segmente stets zusammen auftreten, welche Segmente also eine eigene Gruppe bilden.
Deletionstest = Überprüft wird, welche Ausschnitte in einer Äußerung ich weglassen kann, - allerdings muß auch dabei wieder ein grammtisch korrekter und auch grammatisch vollständiger Satz entstehen.
Zu (2): Den Substitutionstest haben wir in zweierlei Verwendungen erlebt; einmal ging es darum kleinstmögliche bedeutungstragende Segmente zu finden. Zum anderen ging es darum, die größten Guppen innerhalb einer Äußerung bzw. innerhalb eines Satzes zu finden.
Beispielsweise beweisen die folgenden paradigmatischen Austauschverhältnisse, dass eine konjugiertes Verb wie "(ich) lache" aus drei Segmenten besteht:

Vergleichbar belegen die folgenden paradigmatischen Austauschverhältnisse, dass der zugrundegelegte Satz zunächst einmal aus nur zwei 'größtmöglichen' Gruppierungen besteht:

Im Permutationstest ergeben sich die folgenden Umstellungsmöglichkeiten (agrammatische Umstellungen sind mit einem vorangestellten Sternchen gekennzeichnet):

Wende ich den Deletionstest an auf eine Äußerung bzw. einen Satz wie "Gestern hat sich meine alte Tante fürchterlich über Ihre kleinen Enkel aufgeregt", dann ergibt sich der 'Kernsatz' bzw. als 'Kernsatz' "Meine Tante hat sich aufgeregt" (und das ist ein Satz, der sich sehr viel leichter als der Ausgangssatz weiter analysieren läßt).
Zu (3): Lesarten = bei "brennen" gibt es mehrere Lesarten, die sich auch im Valenzrahmen bzw. in der Valenzbeschreibung unterscheiden. Neben "brennen" = 'Feuer' gibt es auch "Das brennt" im Sinne von 'das tut weh' - oder dann "Ich brenne darauf, es nochmals zu versuchen" im Sinne von 'ich möchte unbedingt' (dieses "brennen" hat auch einen anderen Valenzrahmen!).
Wertigkeit von "brennen" in "Das Gebäude brannte lichterloh" = einwertig; dieser eine Aktant ist obendrein obligatorisch (muß also stets auftreten). - Konstruktionen wie "Es brannte lichterloh" stellen einen Sonderfall dar, - das "es" kann hier bewußt, gezielt ausblenden wollen, was denn da brannte. Es ist dennoch nicht mit dem "es" bei Witterungsverben vergleichbar.
Morphologisch-grammatische Charakterisierung des einen Aktanten: Nominalgruppe im Nominativ.
Semantische Charakterisierung des einen Aktanten: Alles, was brennbar ist; Gegenständliches, stets 'konkret', nie 'abstrakt' (es sei denn im Rahmen metaphorischen Sprachgebrauchs), nie 'Sachverhalte'.
Bearbeiten Sie die folgenden Aufgaben:
(1) Was verstehen wir unter den 'Genera des Verbs', - welche haben Sie im Kurs kennen gelernt?
(2) Warum gibt es unterschiedliche Genera des Verbs? Was leisten Sie im Rahmen der sog. 'Diathese'?
(3) Was ist das Besondere am Kasus "Nominativ", was ist das Besondere am Subjekt (in Opposition etwa zu den Objekten und den hier begegnenden Kasusformen)?
(4) Wo spielt im Sprachproduktionsmodell von Levelt die rollentheoretische Struktur eines Satzes eine Rolle?
Zu (1): Gemeint sind Aktiv und (werden-)Passiv; hinzu kommt in den neueren Grammatiken gegebenenfalls die "bekommen"-Periphrase, wie sie vorliegt in "Sie bekam von Ihrem Chef einen Strauß Rosen geschenkt". - Die 'Genera des Verbs' sind grammatikalisierte Diathese-Möglichkeiten, grammatikalisierte Möglichkeiten der diathetischen Abbildung ein- und derselben rollensemantischen Struktur in verschiedene morpho-syntaktische Strukturen.
Zu (2): Unterschiedliche 'Genera des Verbs' im besonderen wie unterschiedliche diathetische Abbildungsmöglichkeiten im allgemeinen realisieren unterschiedliche Gewichtungen und eine darauf aufbauende unterschiedliche 'Perspektive'. Beispielsweise bedeutet das Aktiv zumindest bei Handlungssätzen eine 'agentive Perspektive' (der Agent 'steht im Vordergrund'), wohingegen ein werden-Passiv eine 'Täter-abgewandte Perspektive' ausdrückt. - In Verkürzung dieser Zusammenhänge wird statt von einer 'Täter-abgewandten Perspektive' auch von einer 'passivischen' Perspektive gesprochen. Und eine solche 'passivische Perspektive' kann auch vorliegen, wenn kein werden-Passiv vorliegt, so bei "Das Buch liest sich gut" oder "Mein Fahrrad ist weg".
Zu (3): Dass bei der Verbalisierung eines Sachverhaltes ein bestimmter Ausschnitt zum Subjekt gemacht wird, markiert, dass dieser Ausschnitt den höchsten 'salience-Wert' (die höchste 'kognitive Hervorgehobenheit') trägt; wenn man so will, so wird der Sachverhalt vom Satzglied mit dem höchsten salience-Wert aus 'perspektiviert'. Beispielsweise ist in Handlungssätzen im Aktiv der Agent, der Handelnde, das Subjekt; d.h. dass der Agent den höchsten 'salience-Wert' trägt, dass wir eine 'agentive Perspektive', eine 'Täter-zugewandte Perspektive' realisieren, das z.B. in Opposition zu einer 'passivischen Perspektive', zu einer 'Täter-abgewandten Perspektive', wie sie das werden-Passiv realisiert, bei dem das 'semantische Objekt' zum Subjekt des Satzes gemacht wurde (agens, patiens, semantisches Objekt usw. sind rollensemantische Beschreibungen).
Wollte man mit alltäglichen Begriffen ausdrücken, was mit 'salience' gemeint ist, dann vielleicht so: Der Sachverhaltausschnitt, dem ich den höchsten 'salience-Wert' zuspreche, dieser Sachverhaltsausschnitt ist mir emotional und/oder intellektuell 'am nächsten. Wenn ich beispielsweise aus der Uni komme und mein Fahrrad nicht mehr an der Laterne angeschlossen vorfinde, dann werde ich so gut wie immer Ausrufe produzieren wie "Mein Fahrrad ist weg" (Subjekt = höchster 'salience-Wert' = "meine Fahrrad"), weil mir in diesem Moment zunächst einmal egal ist, dass JEMAND mein Fahrrad (womöglich) gestohlen hat; viel wichtiger ist mir mein FAHRRAD, weil ich nun z.B. nicht mit dem Fahrrad nach Hause fahren kann.
Prozessual gesehen sprechen wir auch von der Subjektivierung eines Sachverhaltsausschnitts; ein bestimmter Sachverhaltsausschnitt wird in der morpho-syntaktischen Struktur zum Subjekt gemacht. - Die Subjektivierung (und die Zuordnung des jeweils höchsten 'salience-Wertes') hat nichts zu tun mit der Thema-Rhema-Struktur (hier im Sinne des sog. Prager Strukturalismus, zu dem auch Trubetzkoy - siehe ganz zu Anfang dieses Teils - gehörte) bzw. prozessual mit der Thematisierung eines Sachverhaltsausschnitts zu tun. Und weder die Subjektivierung noch die Thematisierung hat mit der über Stellung oder / und Intonation realisierten kommunikativen Hervorhebung zu tun, wie sie am deutlichsten bei kontrastiver Betonung in Erscheinung tritt, - vgl. "Er hat das Fahrrad nicht VERSCHENKT, sondern GESTOHLEN bekommen".
Zu (4): Die (universelle, d.h. außereinzelsprachliche) semantische Rollenstruktur ist bei Levelt der output der Planungsprozesse bzw. der konzeptuellen Vorbereitung ("conceptualizer") - und zugleich der input in die Formulierungsprozesse ("formulator"), genauer: der input in die grammatische Enkodierung ("grammatical encoding"):
